Contents
param serie: parametric examples
The serie param consists of store-buffering examples for x86, where we insert some noise between the write and read of each thread. The tools must derive a fence (at least) between each pair of write and read to prevent a reordering on x86.
1 If-then-else diamonds
We first exercise the tools on the program presented in the Fig. 1. The equivalent transition system for trencher, the rmm program for memorax, the promela-like program for remmex and x86 assembly-like program for offence that we use in this comparison are available here.
1 volatile int turn0, turn1; 2 volatile int x0, x1; 3 4 void* th1(void* arg) { 5 while(1) { 6 x0 = 1; 7 REPEAT ( 8 if(turn0 == 0) 9 turn0 = 1; 10 else 11 turn0 = 0; 12 ) 13 if(x1) {} 14 } 15 } 16 17 // symmetric 18 void* th2(void* arg) { 19 while(1) { 20 x1 = 1; 21 REPEAT ( 22 if(turn1 == 0) 23 turn1 = 1; 24 else 25 turn1 = 0; 26 ) 27 if(x0) {} 28 } 29 }
Figure 1: Program turn.c in C with a parametric number of if-then-else diamonds.
The store-buffering happens between the shared variables x0 and x1. The program is parametrised by the number of if-then-else diamonds arising in the middle of the code (lines 8-11). This code actually alternates the value of respectively turn0 and turn1 in thread 0 and 1 across the iterations. turn0 and turn1 are actually only updated and read by one thread. We use this trick to force the tools to explore all the alternating paths during an execution.
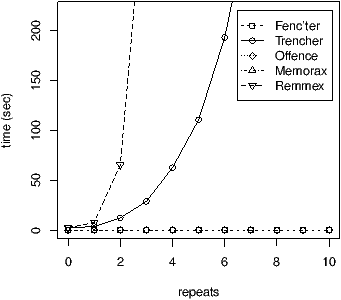
As displayed in the top Fig. 2, memorax timeouts with 2 diamonds. We explain these difficulties by the fact that memorax needs assertions to target so that it restores the sequential consistency of the program with respect to these assertions. However, we had to use one additional shared variable in our program so that we could check whether the store-buffering was happening. trencher and remmex explore all the traces in the diamonds, logically leading to an exponential curve. After discussion with the authors, we understood that the alternation in remmex’s curve was due to the automaton acceleration, which is efficient only when an iteration of the while loop will not alternate the final value of turn0. In practice, this means that the acceleration happens for the even numbers of diamonds, which explains the aspect of the curve. Even though musketeer does not execute each path, it still has to explore the full graph to find critical cycles, including all the diamonds. This explains why it is faster than the two former tools, but still exhibits an exponential trend. Thanks to its mapping approach, offence avoids all the diamonds reasoning.
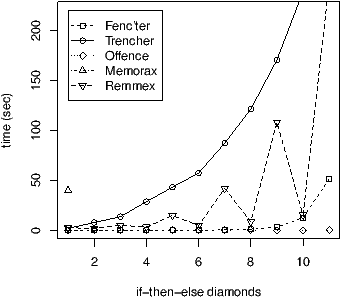
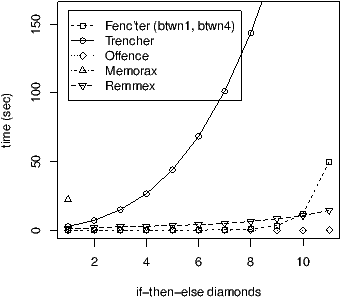
In the bottom Fig. 3, we impose at line 7 that turn0 (respectively turn1) always holds the same value at the beginning of each iteration. In this setting, remmex’s acceleration is efficient for all the iterations in Fig. 4. The exponential trend is nevertheless still perceptible towards the end of the curve.
1 volatile int turn0, turn1; 2 volatile int x0, x1; 3 4 void* th1(void* arg) { 5 while(1) { 6 x0 = 1; 7 turn0 = 0; 8 REPEAT ( 9 if(turn0 == 0) 10 turn0 = 1; 11 else 12 turn0 = 0; 13 ) 14 if(x1) {} 15 } 16 } 17 18 // symmetric 19 void* th2(void* arg) { 20 while(1) { 21 x1 = 1; 22 turn1 = 0; 23 REPEAT ( 24 if(turn1 == 0) 25 turn1 = 1; 26 else 27 turn1 = 0; 28 ) 29 if(x0) {} 30 } 31 }
Figure 3: Program turn2.c in C with a parametric number of if-then-else diamonds.
2 Three threads with noise
In Fig. 5, we introduce a third program. We remove from the previous examples the diamond structures, but we keep the repetitions of writes and reads to the variables turn0 and turn1. We add a third thread, which is identical to the first one, except that it updates its own noise variables turn2. The program thus exhibits two store-bufferings, one between thread 1 and thread 2, and one between thread 2 and thread 3.
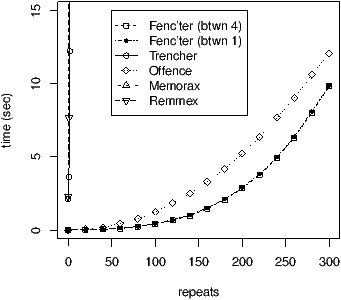
With this configuration, all the tools based on an operational semantics (memorax, remmex, trencher) quickly diverge, as shown in Fig. 6. In contrary, offence and musketeer are handling quite well these programs: in Fig. 7, we have to unzoom to 300 repetitions of the noise in the middle of the threads to observe a significant increase of the curve. musketeer happens here to be faster than offence. We experimented musketeer with two encodings. We implemented the encoding of the paper, written btwn1, which is based on that appear between each delay, and a thinner encoding only involving the that are genuinely involved in the interactions of critical cycles. We write the latter btwn4. In Fig. 7, we observe that the thinner encoding does not significantly improve the time of computation.
1 volatile int turn0, turn1, turn2; 2 volatile int x0, x1; 3 4 void* th1(void* arg) { 5 while(1) { 6 x0 = 1; 7 REPEAT ( 8 if(turn0 == 0) {} 9 turn0 = 1; 10 turn0 = 0; 11 ) 12 if(x1) {} 13 } 14 } 15 16 // symmetric to th1 17 void* th2(void* arg) { 18 while(1) { 19 x1 = 1; 20 REPEAT ( 21 if(turn1 == 0) {} 22 turn1 = 1; 23 turn1 = 0; 24 ) 25 if(x0) {} 26 } 27 } 28 29 // identical to th1 30 // (except the noise) 31 void* th3(void* arg) { 32 while(1) { 33 x0 = 1; 34 REPEAT ( 35 if(turn2 == 0) {} 36 turn2 = 1; 37 turn2 = 0; 38 ) 39 if(x1) {} 40 } 41 }
Figure 5: Program three.c in C with three threads and a parametric number of noise variables.